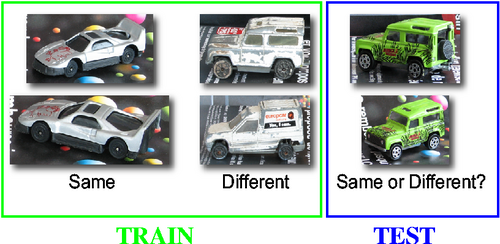
Our purpose is to compute a similarity measure between two images. That measure should deal with never seen objects (never seen car models, never seen faces, ...) and should be robust to modifications in pose, background, light. It is trained with pairs of images labeld "Same" or "Different". This is less informative than fully labeled training images ("Car model 1", "Car model 2", ...) but much cheaper to obtain.
Our algorithm is evaluated on three public datasets, and also on our own dataset of toy cars. It can be downloaded here (23Mb). The archive contains the images and a metadata file (pairs.txt).
The pairs of images of the toycar dataset are made from these
vehicles:
You can download a binary (~1Mb) of our algorithm for linux machines. It should work on many distributions, but we have only tested Mandrakelinux 10.1 for i586, kernel 2.6. The binary requires the following standard libraries: linux-gate.so.1, libpng.so.3, libjpeg.so.62, libpthread.so.0, libstdc++.so.6, libm.so.6, libgcc_s.so.1, libc.so.6, libz.so.1, /lib/ld-linux.so.2.
NOTE! This binary is a reimplementation of our CVPR07 algorithm, for simplicity reasons it does NOT contain geometry based split conditions, which usually increase the overall EER-PR of 1%.
Help about command line options is obtained by: pRazSimiERCF --help
The best way to understand the behavior of the algorithm is to try it on our toy car dataset.
Use randseed=1 to reprocude the following result, or randseed=0 to
initizalize the random number generator with the current time.
| Algorithm |
Eric Nowak and Frédéric Jurie,
Learning Visual Similarity Measures for Comparing Never Seen Objects,
Computer Vision and Pattern Recognition 2007 (CVPR'07).
pdf, algorithm in section 2.
You can also download the slides of the talk. |
| Binary | for linux (~1Mb) |
| Dataset | toycars dataset (~23Mb) |
| Command line | pRazSimiERCF -K -randseed 1 -verbose 3 -ntrees 5 -maxleavesnb 25000 -nppL 100000 -ncondtrial 1000 -nppT 1000 -wmin 15 -wmax 100 -neirelsize 1 -svmc '0.000001 0.0001 0.01 1' .png /path/to/dataset/imstdsize/ /path/to/dataset/pairs.txt res |
| Output files | outputs of the previous command line (~6Mb), shows the trees, mem usage, detailed performance information, etc. |
| Performance (SVM C=1) |
|
The binary allows to visualize the patch pairs used to learn the trees.
The following patch pairs have been produced with:
pRazSimiERCF -K -randseed 1 -verbose 3 -ntrees 5
-maxleavesnb 25000 -nppL 10 -visutreepairs -ncondtrial 1000 -nppT 1000
-wmin 15 -wmax 100 -neirelsize 1 -svmc 1
.png /path/to/dataset/imstdsize/ /path/to/dataset/pairs.txt res
| Pair label | Random patch in first image | Corresponding patch in second image |
|---|---|---|
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Different |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |
| Same |  |  |