On the Importance of Visual Context for Data Augmentation in Scene Understanding
Abstract
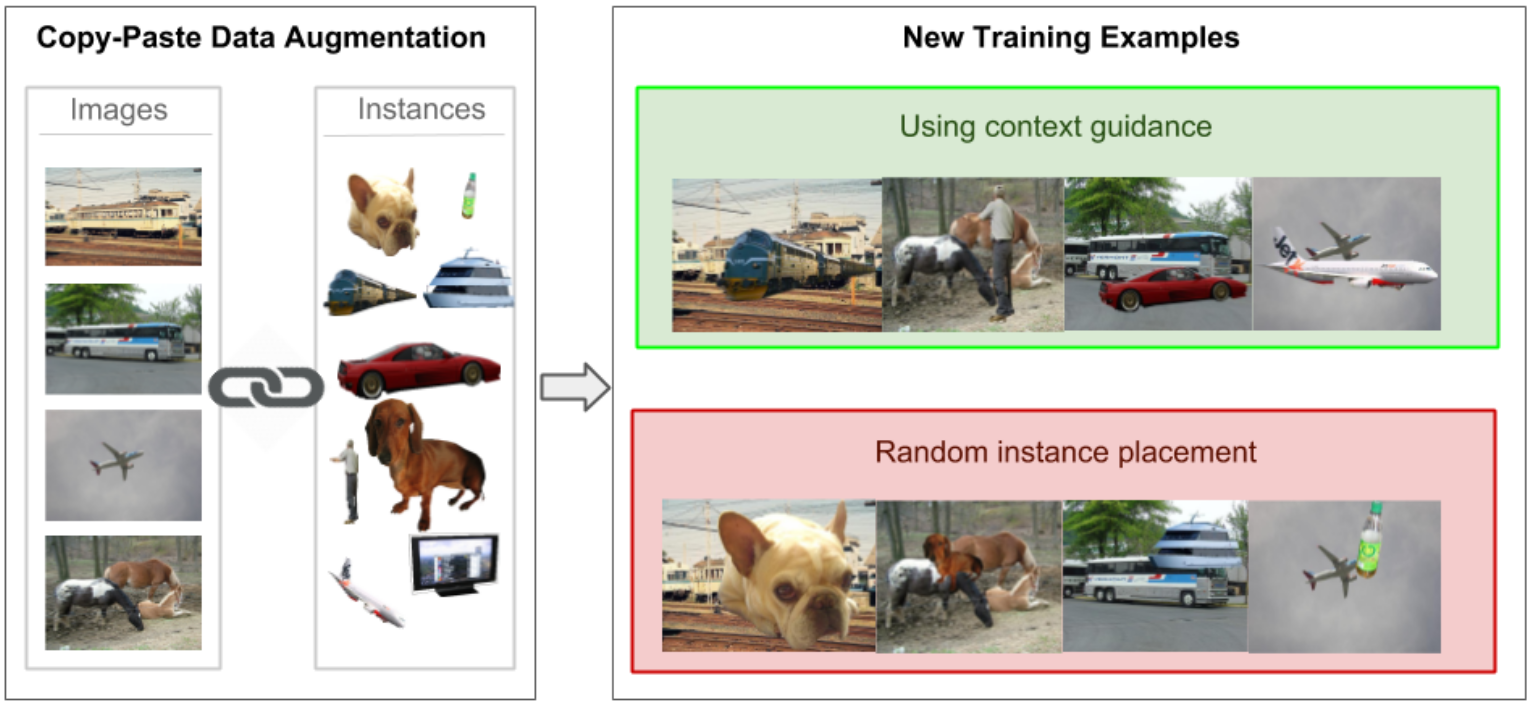
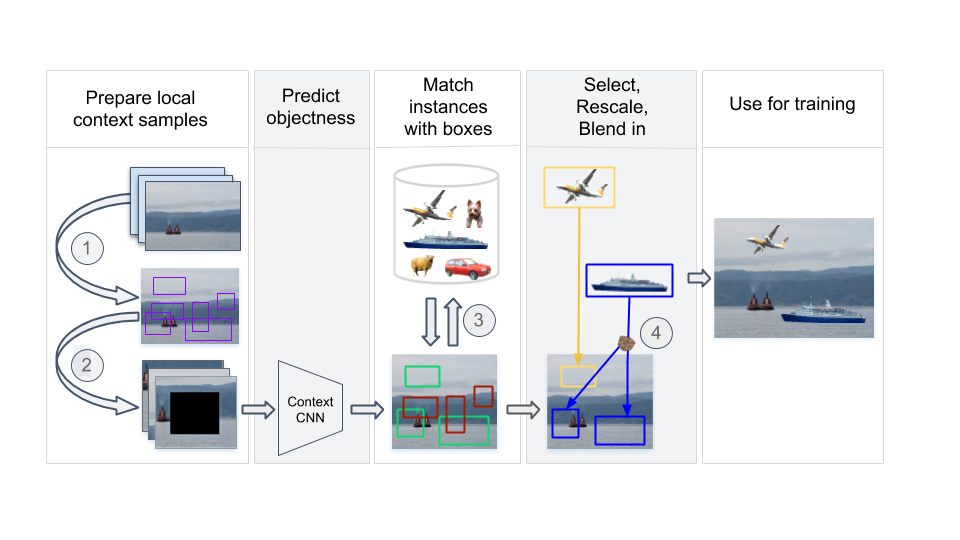
Performing data augmentation for learning deep neural networks is known to be important for training visual recognition systems. By artificially increasing the number of training examples, it helps reducing overfitting and improves generalization. While simple image transformations such as changing color intensity or adding random noise can already improve predictive performance in most vision tasks, larger gains can be obtained by leveraging task-specific prior knowledge. In this work, we consider object detection and semantic segmentation and augment the training images by blending objects in existing scenes, using instance segmentation annotations. We observe that randomly pasting objects on images hurts the performance, unless the object is placed in the right context. To resolve this issue, we propose an explicit context model by using a convolutional neural network, which predicts whether an image region is suitable for placing a given object or not. In our experiments, we show that by using copy-paste data augmentation with context guidance we are able to improve detection and segmentation on the PASCAL VOC12 and COCO datasets, with significant gains when few labeled examples are available. We also show that the method is not limited to datasets that come with expensive pixel-wise instance annotations and can be used when only bounding box annotations are available, by employing weakly-supervised learning for instance masks approximation.Augmentation pipeline
Project Papers
BibTeX
@inproceedings{dvornik2018modeling,
title={Modeling Visual Context is Key to Augmenting Object Detection Datasets},
author={Dvornik, Nikita and Mairal, Julien and Schmid, Cordelia},
booktitle={{IEEE European Conference on Computer Vision (ECCV)}},
year={2018}
}
Code
Code for the conference paper is available on GitHub.
Acknowledgements
This work was supported by a grant from ANR (MACARON project under grant number ANR-14-CE23-0003-01), by the ERC grant number 714381 (SOLARIS project), the ERC advanced grant ALLEGRO and gifts from Amazon and Intel.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright. This page style is taken from Guillaume Seguin.