Synthetic Datasets
The synthetic dataset is composed of 10000 amount of 2 dimensional points belonging to 5 different classes. The data points are randomly sampled from Gaussian distributions with given mean and variance values. We have 6 different datasets with different difficulty levels. The difficulty of the datasets are determined by the mean and variance of the Gaussians the samples are taken from. The whole dataset is divided in two parts with the same size as training and test set.
i. Training datasets

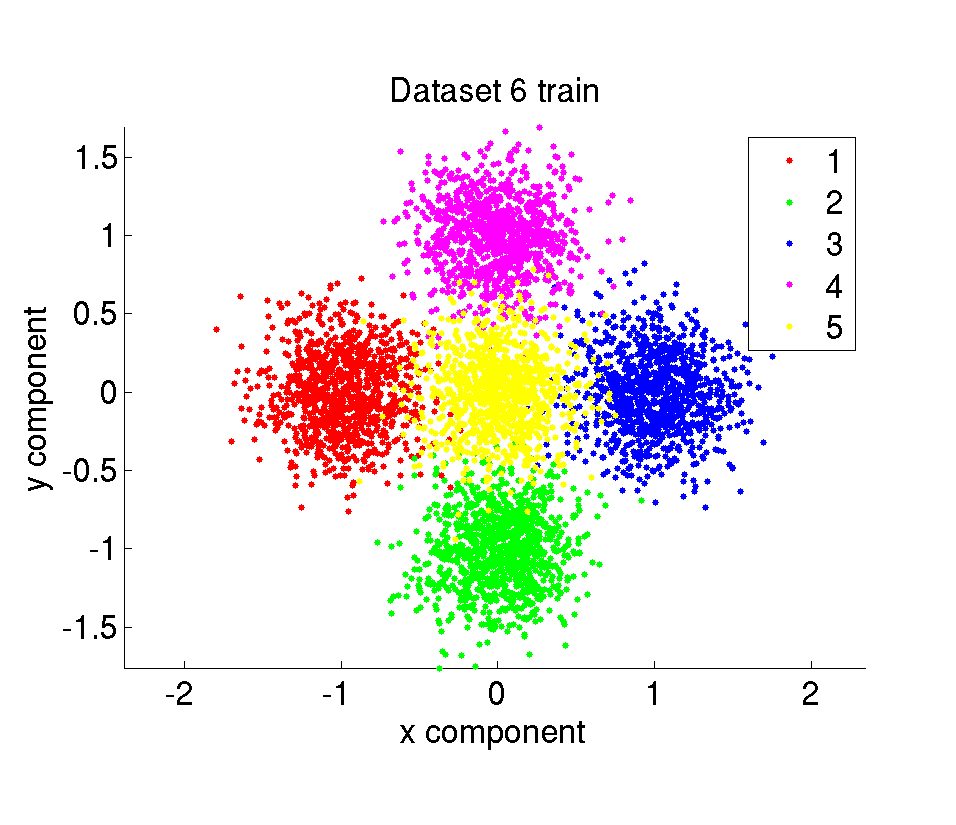
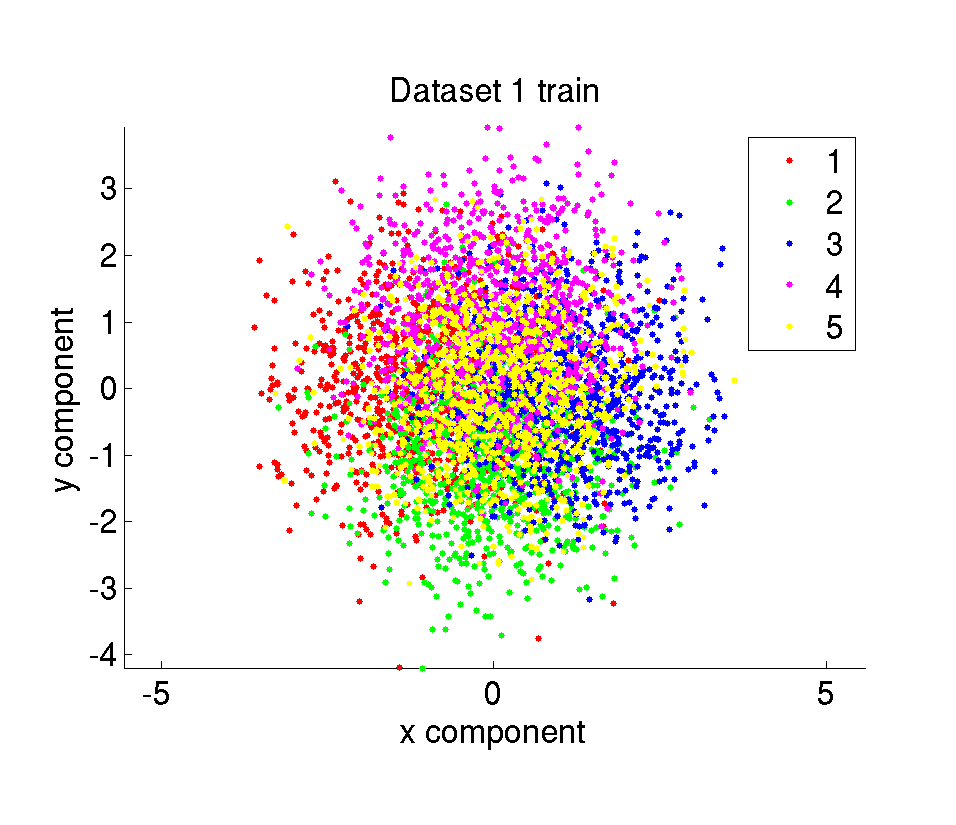
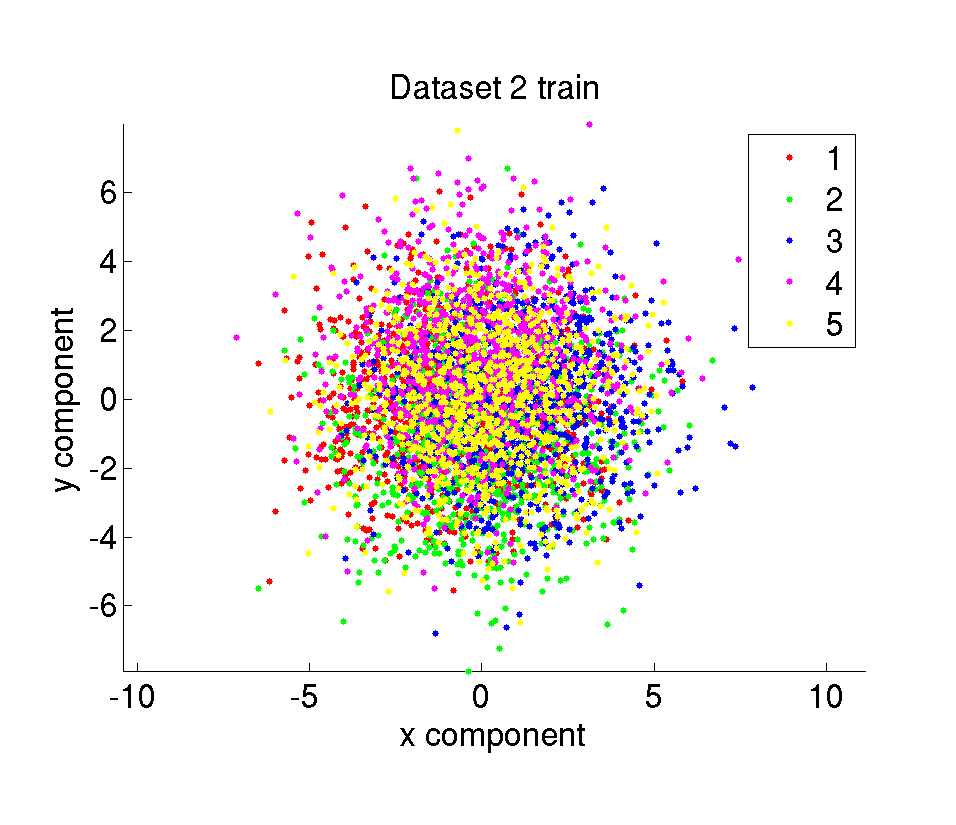
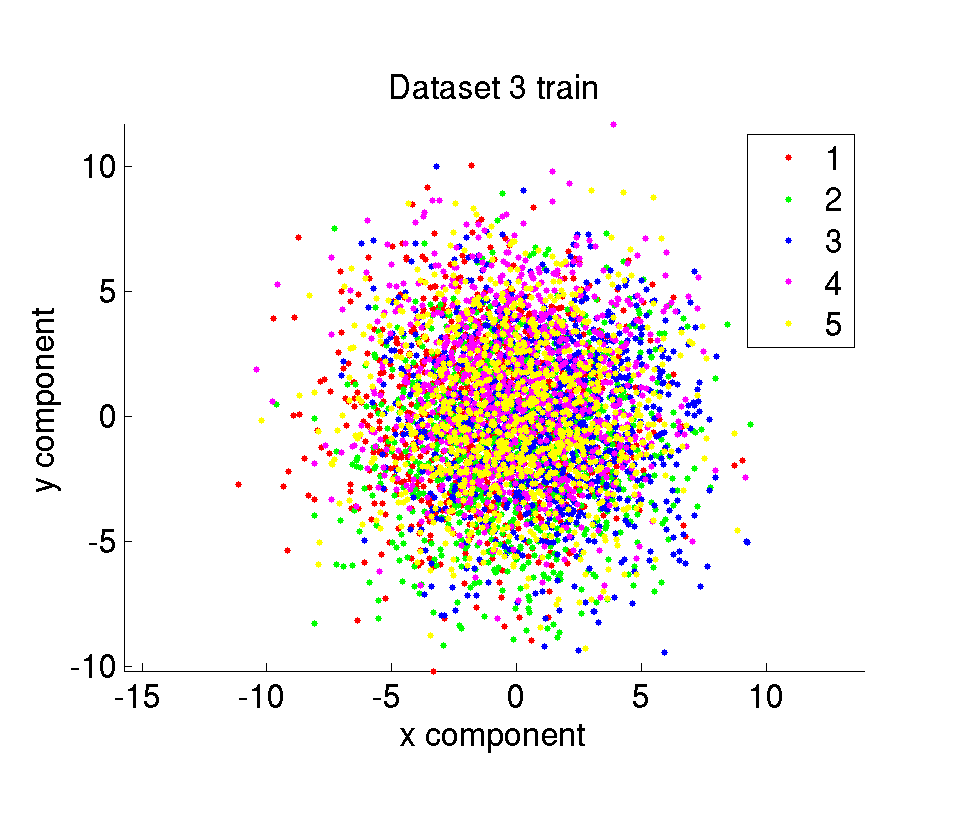
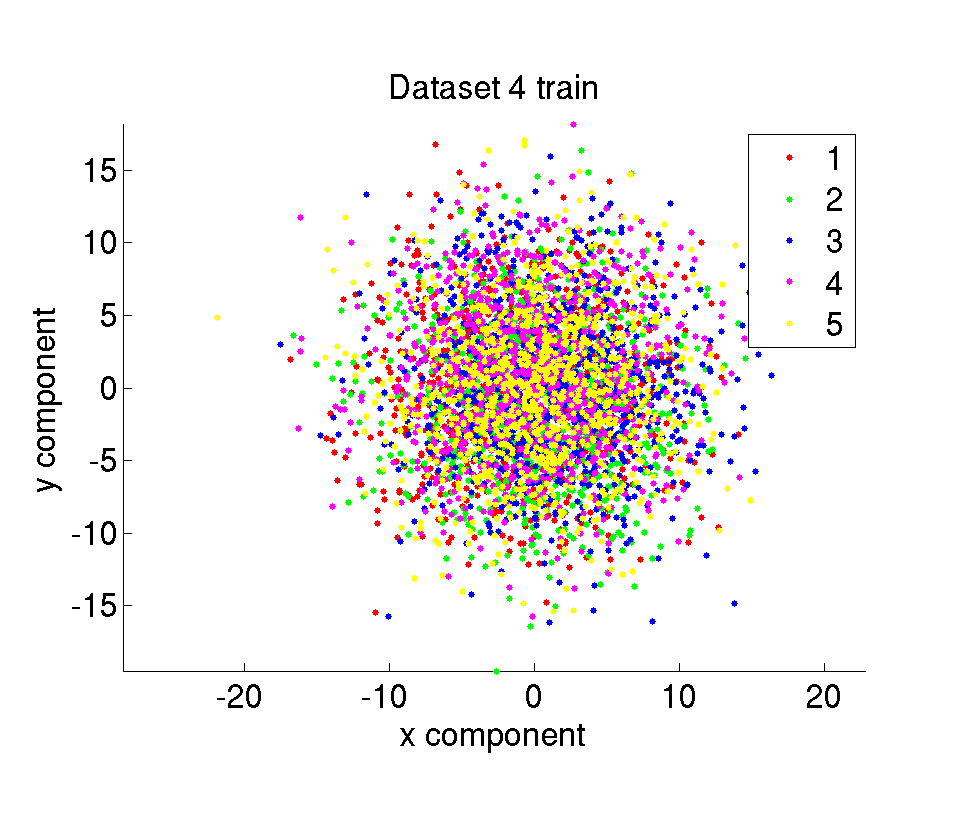
ii. Test datasets
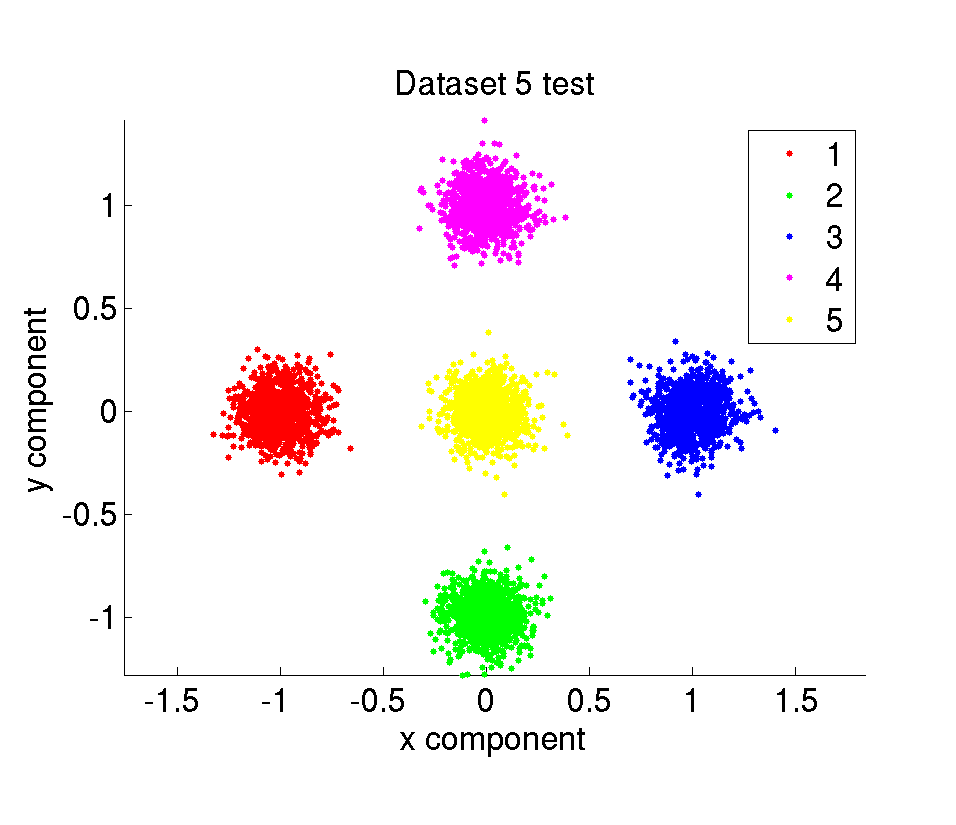
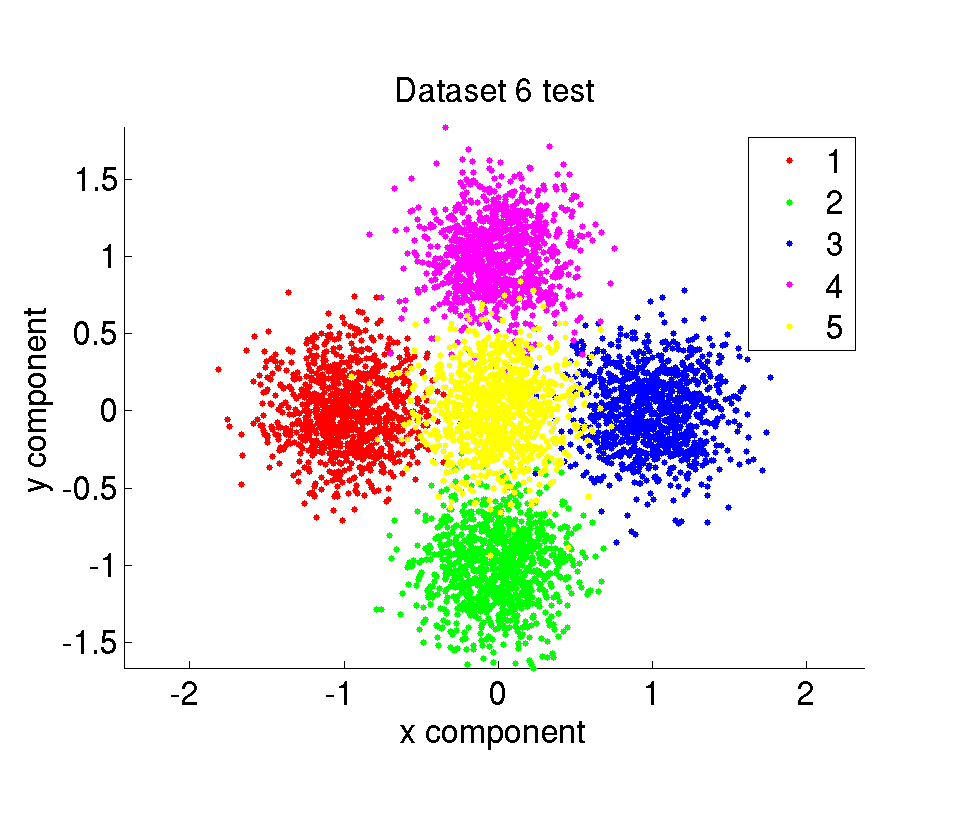
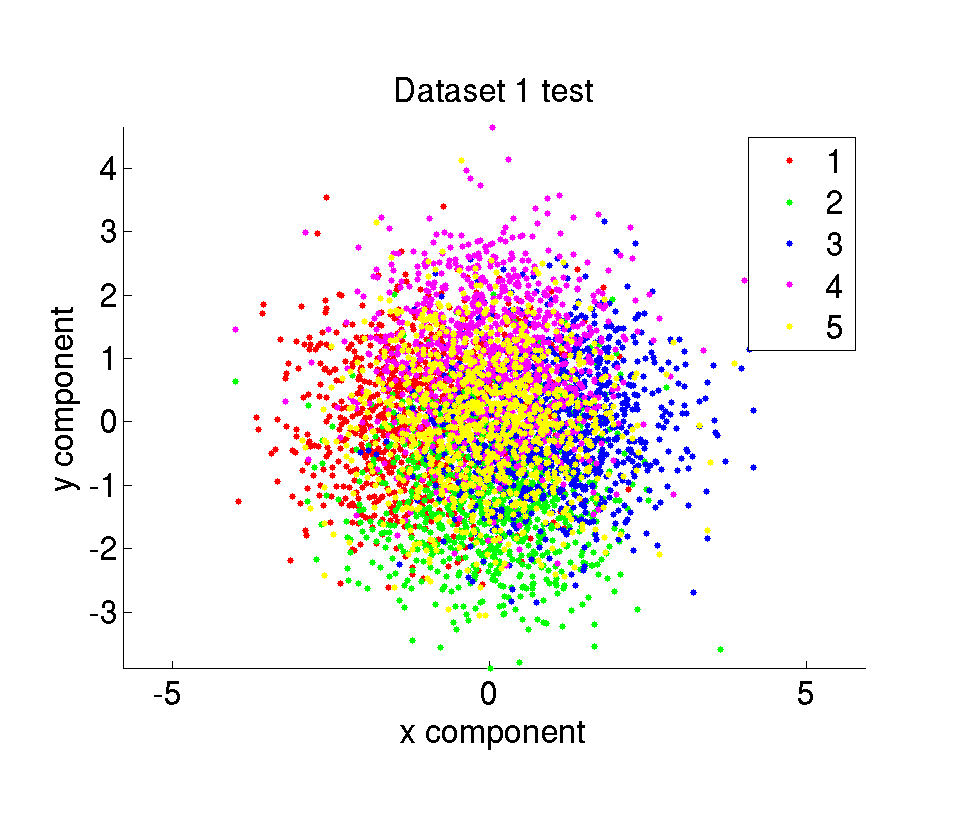
The synthetic dataset is composed of 10000 amount of 2 dimensional points belonging to 5 different classes. The data points are randomly sampled from Gaussian distributions with given mean and variance values. We have 6 different datasets with different difficulty levels. The difficulty of the datasets are determined by the mean and variance of the Gaussians the samples are taken from. The whole dataset is divided in two parts with the same size as training and test set.
i. Training datasets
ii. Test datasets