Research Directions
Thoth's research on learning based approaches for visual scene interpretation can be divided into the following areas. For more information see our publications.
Video Segmentation

|
Learning Motion Pattern in Videos CVPR'17 |

|
Learning Video Object Segmentation with Visual Memory ICCV'17 |
Object detection on images

|
BlitzNet: A Real-Time Deep Network for Scene Understanding ICCV'17 |
|
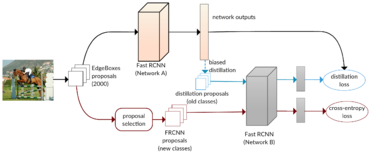
Incremental Learning of Object Detectors without Catastrophic Forgetting ICCV'17 |
Human pose estimation

|
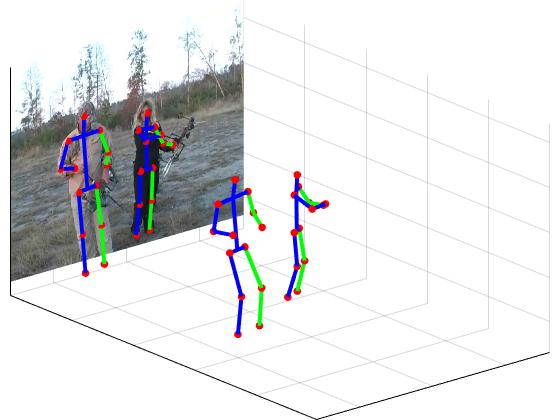
MoCap-guided Data Augmentation for 3D Pose Estimation in the Wild NIPS'16 , IJCV'18 |
|
LCR-Net: Localization-Classification-Regression for Human Pose CVPR'17 , arXiv'18 |
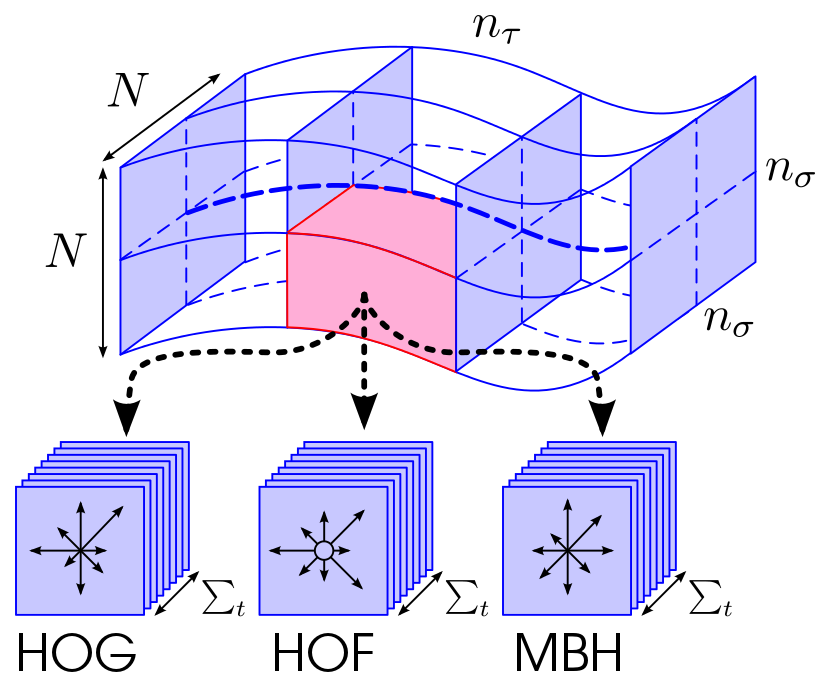
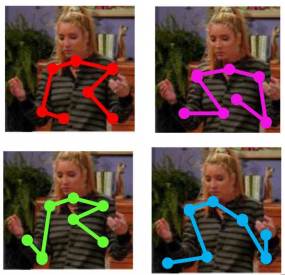
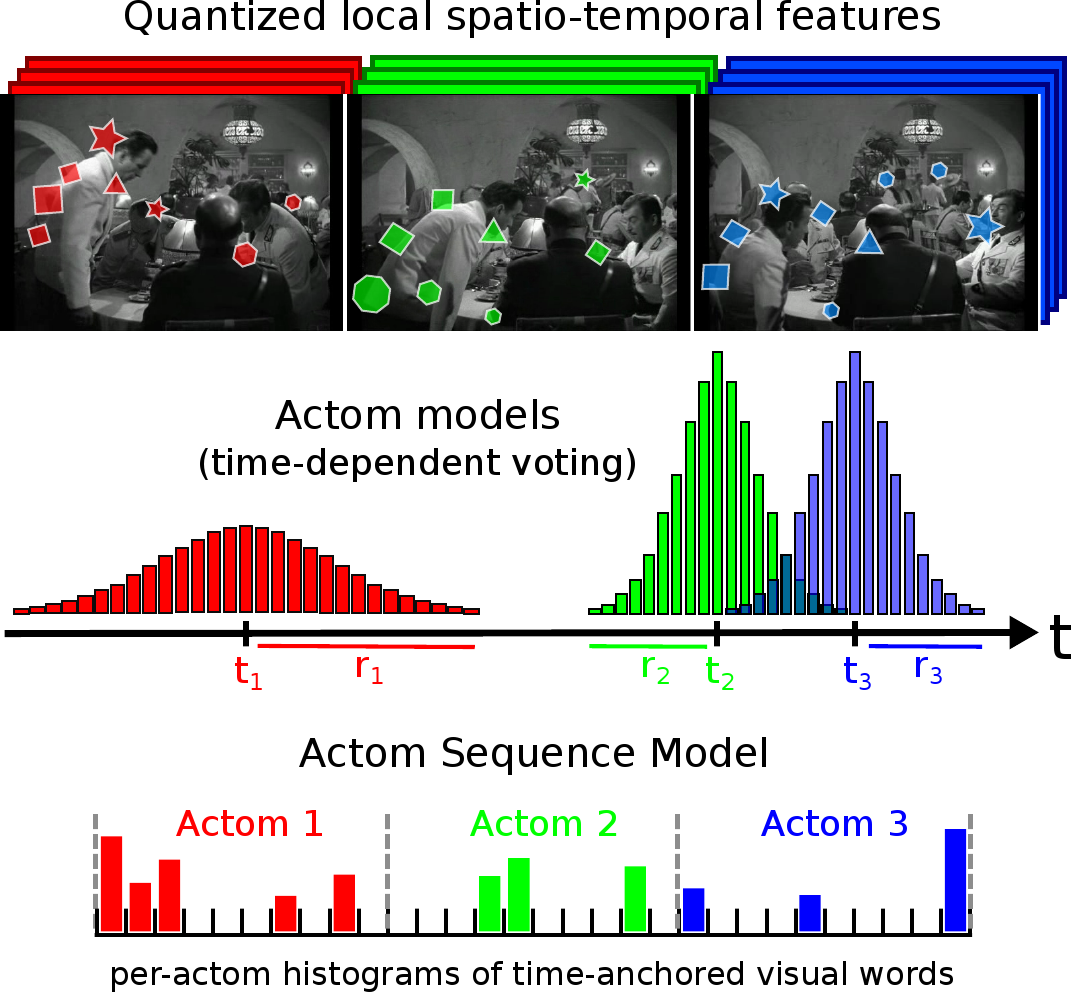
Action recognition in videos
Weakly-supervised visual modeling

|
Multi-fold MIL Training for Weakly Supervised Object Localization CVPR'14 |

|
Finding Actors and Actions in Movies ICCV'13 |
|
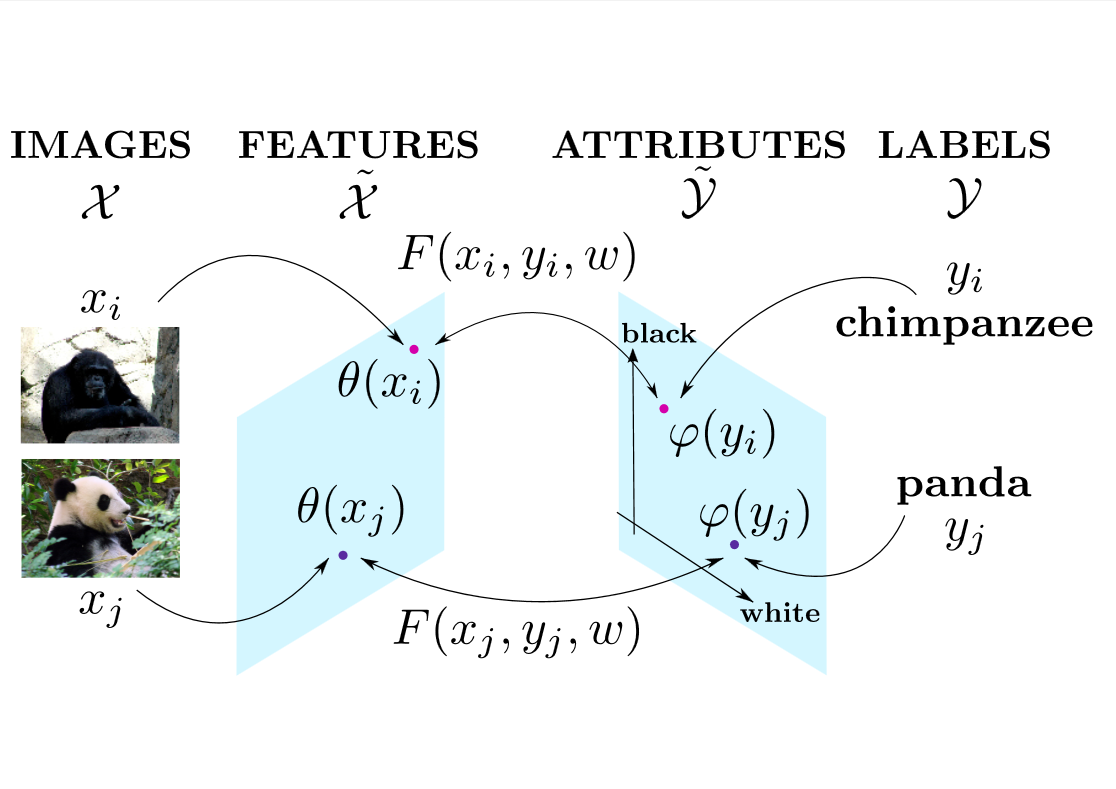
Label-Embedding for Attribute-Based Classification CVPR'13 |

|
Spatio-Temporal Object Detection Proposals ECCV'14 |
Large-scale classification
|
Large-scale image classification with trace-norm regularization CVPR'12 |

|
Good Practice in Large-Scale Learning for Image Classification PAMI'14 |
|
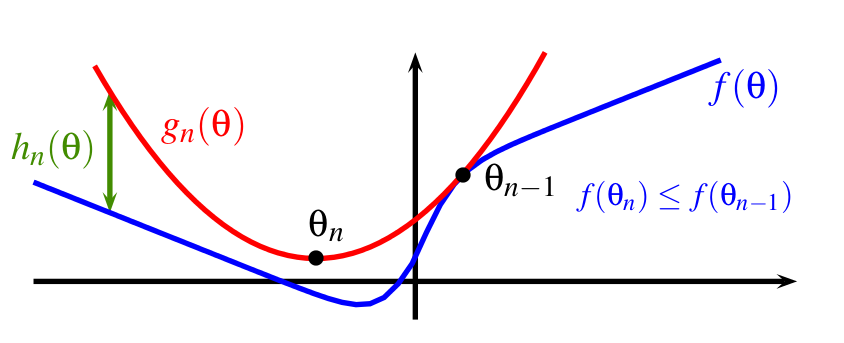
Optimization with First-Order Surrogate Functions ICML'13 |
|
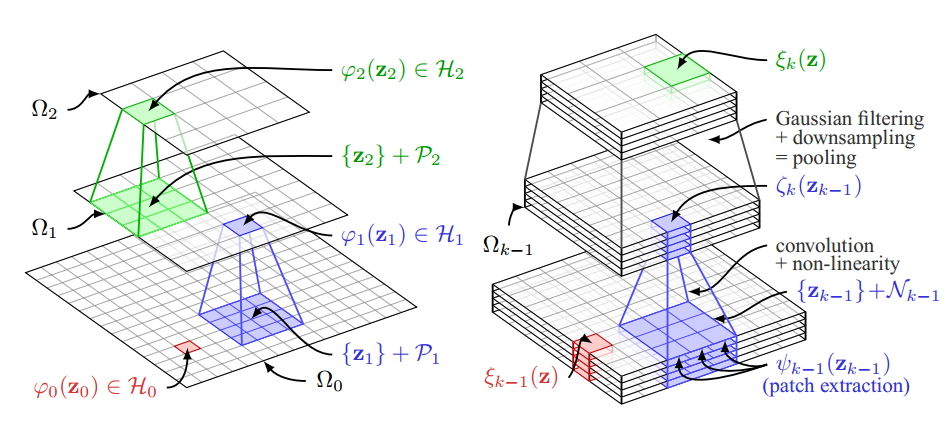
Convolutional Kernel Networks NIPS'14 |
Large-scale retrieval
|
Aggregating local image descriptors into compact codes PAMI'12 |
|
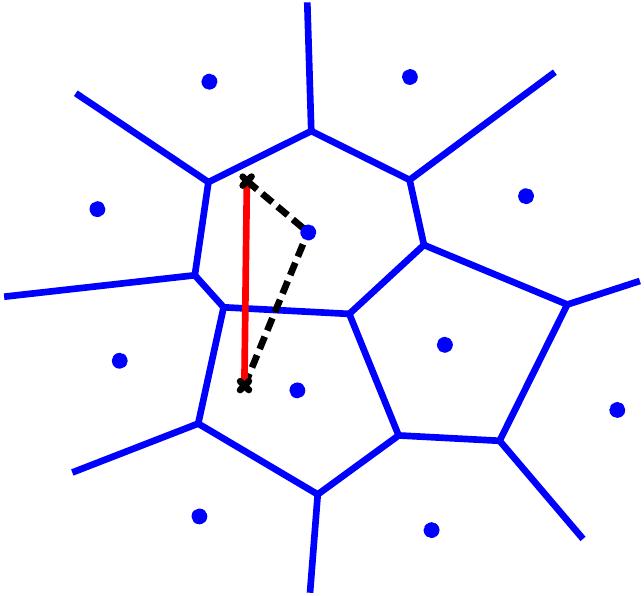
Product Quantization for Nearest Neighbor Search PAMI'11 |

|
Event retrieval in large video collections with circulant temporal encoding CVPR'13 |
|
Combining attributes and Fisher vectors for efficient image retrieval CVPR'11 |